In the suggested script you posted before you used LIKE which I presume is same as contains.
Encase PMSDepartment tags are used in another tag column I guess this could be set to ' {\"TN\":\"PMSDepartment\",\"TV\":\" ' + gl_account + ' \"} '
Which would work and be specific enough to not get any errors.
Although looking again at yours the escape would be % rather than \ right?
Next issue would be getting a list of used PMSDepartment values, it would be nice to keep this dynamic rather than specify a list.
EDIT: ok so it would be more like ’ %{“TN”:“PMSDepartment”,“TV”:" ’ + PMSDepartment + ’ "}% ’
Getting there, think this is close (at least for getting the department/custom tag totals;
SELECT SUM(o.[Price]) AS [DepartmentTotal]
FROM [Orders] o JOIN [Payments] p ON p.[TicketId] = o.[TicketId] JOIN [MenuItems] m ON o.[MenuItemId] = m.[Id]
WHERE 1=1 AND p.[Name] <> 'Room Post' AND m.[CustomTags] like '%{"TN":"PMSDepartment","TV":"10002"}%'
Obviously that is set to a specific tag and would need the TV to be a variable.
Still back to the same issue of how to generate a list of unique CustomTags for PMSDepartment.
OK, think while working on generating a list I have also possibly found a simpler way to get a tag value out of the CustomTags column which will save a loop in the other script;
Still needs a bit of work but am having to call it a night.
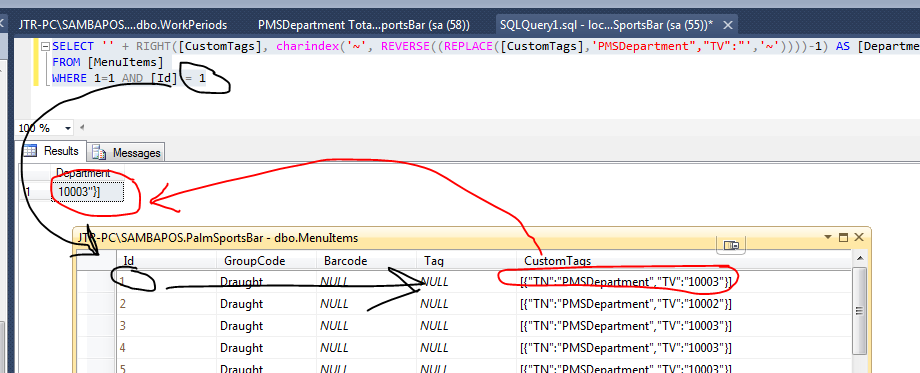
SELECT '' + RIGHT([CustomTags], charindex('~', REVERSE((REPLACE([CustomTags],'PMSDepartment","TV":"','~'))))-1) AS [Department]
FROM [MenuItems]
WHERE 1=1 AND [Id] = 1
HOWEVER this would give an issue of not every order had a PMSDepartment Tag as gives an error because of the -1.
In theory all would have a PMSDepartment but @QMcKay if you could suggest an alternative/solution to avoid any issues.
Next would be stripping the trailing characters following the first " once the leading characters have been removed.
QMcKay If you could help me with stripping the excess characters for the tag string the DISTINCT fUnction should hopefully allow a list of departments to be generated to feed into a similar loop from the room post but feeding PMS department/gl_account into the filter rather than the order ID.
Parsing JSON via SQL is a PITA, and though it can be done, I don’t recommend it, especially since you have JSON.parse() in JScript.
If the TV value is always 5 characters, then just do SUBSTRING(<val>,1,5)
SELECT DISTINCT '' + SUBSTRING(RIGHT([CustomTags], charindex('~', REVERSE((REPLACE([CustomTags],'PMSDepartment","TV":"','~'))))-1),1,5) AS [Department]
FROM [MenuItems]
WHERE 1=1 AND [Id] = 1
But again, use the parser at your disposal, if you can.
But using the parser would then require a loop for each menu item where as just stripping the characters up to the " before value and after the " after would mean a distinct function would give a straight unique list SQL result
If not would then need to loop build the list in jscript, presume change to array and work out/ask emre if not helper to reduce list/array to district values only.
The code would not necercerally be 5 characters
I was hoping a second function after the first charindex might be able to take the first instance of a character (the " after the values before value have been stripped) and then remove everything after leaving a list of only PMS department values.
And you might also have more Products Tags as well, yes/no? It just gets messy, especially when some products have multiple tags, while others do not, and then the Tags appear in different order inside the JSON. The cleanest and most reliable way in this case is to go with the parser. Then do some “magic” in JS to determine DISTINCT. Let me see what I can come up with to illustrate. May have to wait until tomorrow though.
However regardless of any other tags the tag name will be unique yer?
So of we strip the front first braced on the tag name PMS department as have done to day we then know that the first " will be the end of the value!
I have been taking in to account the fact of other departments and orders so far ;-).
If there is a equivilent of charindex to specify the first (which I think if you say left or right it does anyway) we can strip and save the loops.
If we do loops we are then looking at potential of 5/6 loops per product X number of product which could lead to 1000 loops easily, while building a list and then district the list, if we can generate a column of just the district tag values it would be a lot less intensive script…
The only missing part to generating the list is stripping the trailing characters from the string and we are there…
Not that I’m questioning your expertise I just feel more comfortable limiting the number of loops and keeping the variables as values I can actually see wherever posible.
I have looked into it before. So before trying to re-invent the wheel, you can get and set a Stored Procedure in your DB and not worry about it any more. Look here…
I also just read that SQL 2016 will have built-in parsing methods…
Additional capabilities in SQL Server 2016 include:
Additional security enhancements for Row-level Security and Dynamic Data Masking to round out our security investments with Always Encrypted.
Improvements to AlwaysOn for more robust availability and disaster recovery with multiple synchronous replicas and secondary load balancing.
Native JSON support to offer better performance and support for your many types of your data.
SQL Server Enterprise Information Management (EIM) tools and Analysis Services get an upgrade in performance, usability and scalability.
Faster hybrid backups, high availability and disaster recovery scenarios to backup and restore your on-premises databases to Azure and place your SQL Server AlwaysOn secondaries in Azure.
Hmmm, that sounds very benificial for those using direct SQL to call info given that states, product tags and custom entity data is all stored in Json format
Fair shout, when is 2016 expected release?
Sorry sure a Google search would respond and 2016 although not a giveaway suggests next year?
Unfortunately this project has a deadline of Jan 25 by which time it needs to be production env ready.
Basically you are adding a function to the Database. Once it is there, you can use it any time you want. So if you create the function in the DB and call it parseJSON(), then you can do this anytime:
SELECT parseJSON([CustomTags]) FROM MenuItems WHERE Id=1
I have added the function code from that article to my DB. Now I am trying to figure out how to use it, because the above does not work
Even with the parsing function in the DB, there is much more to do to get data in a format that we can consume…
USE [SambaPOS5]
declare @jsondata nvarchar(max) = ''
declare @tagcount int = 0
declare @i int = 1
declare @tbl_jd table (
elementID int not null
,sequenceNo int not null
,parentID int null
,objectID int null
,nm varchar(255) null
,stringVal varchar(255) null
,valType varchar(10) null
)
declare @tbl_json table (
p int not null
,n varchar(255) not null
,v varchar(255)
)
declare @tbl_tags table (
Id int not null
,Tag varchar(255) not null
,Val varchar(255) null
)
-- get Product Tags
select @jsondata=CustomTags from MenuItems where Id=2
--select @jsondata
--run it through the parser
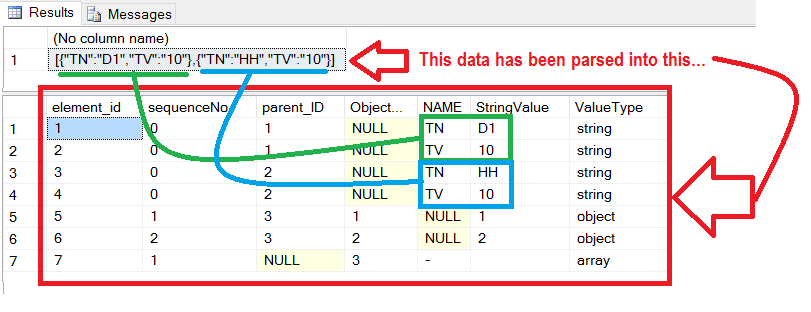
insert into @tbl_jd
select * from parseJSON(@jsondata)
--select * from @tbl_jd
--build our own JSON table with just the elements we want
insert into @tbl_json
select parentID, nm, stringVal from @tbl_jd
where 1=1
and parentID in (select distinct stringVal from @tbl_jd where valType='object')
--get the count of unique Tags
SET @tagcount = (SELECT COUNT(DISTINCT(p)) FROM @tbl_json)
print @tagcount
--select * from @tbl_json
-- build pivoted Tag/Value data
WHILE @i<=@tagcount
BEGIN
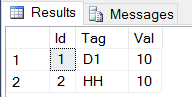
INSERT INTO @tbl_tags (Id,Tag,Val)
SELECT p,v,'' from @tbl_json where n='TN' and p=@i
UPDATE @tbl_tags set Val=(SELECT v FROM @tbl_json where n='TV' and p=@i)
SET @i=@i+1
END
--show what we have done
select * from @tbl_tags
Output:
All that, and we processed 1 Product record. Now we need to go through all of the Products… sheesh!
Might need to look into this other parser function - it might suit our needs better:
If it were part of a larger array with multiple sub arrays with repeating value names this would be more valid but for use on states, tags and custom data fields these are all single line/array lists with unique value names prefixing each value, as such we can use the name as a point of reference as I did above to bring the corresponding value to front of the string. Doing that means we just need to strip any trailing values.
I know what your saying but parse is much more vital with a multi tiered data set here there would’ve repeating value names/prefixes across arrays.
Here is the thing though… We can code this up for your use-case for gl_x or PMSDep or whatever. That makes assumptions that we know what the Tag Names are and which order they are stored in. For example, if I want a value out of this:
[{"TN":"D1","TV":"10"},{"TN":"HH","TV":"10"}]
The code will change whether I am looking for the D1 value or the HH value. And I also need to assume that both of the values exist, and always in the same order. These assumptions will make the code very simple. But I don’t know if I am comfortable with the assumptions; that is, I don’t know if those assumptions are guaranteed to be true all the time.
What I am doing here is more universal and in the end will work for everybody and everything when it comes to SambaPOS JSON data, and picking out a Tag or a State value.
I can stop now for a bit, and code for your case… it won’t take long to do, and then I can go back to this other stuff… I have interest in doing it because I believe it will be useful.
-- [{"TN":"D1","TV":"10"},{"TN":"HH","TV":"10"}]
declare @tagName varchar(30) = 'HH'
declare @tagNameLen int = len(@tagName)
declare @validx int = @tagNameLen+len('","TV":"')
SELECT DISTINCT replace(substring([CustomTags],charindex(@tagName,[CustomTags])+@validx,10),'"}]','')
FROM [MenuItems]
WHERE 1=1
AND [CustomTags] like '%{"TN":"'+@tagName+'","TV":"%"}%'