I am trying to get my head around customer reports and report tags etc but I am struggling on what I guess is a rather basic issue…
I have used… {REPORT ENTITY DETAILS:E.Id,E.Balance.sum:(ET=Customers):{0}::($2!=0):,}
to return a list of Entity IDs for Customers who owe me money.
With this list of Entity IDs I want to get a list of tickets belonging to these entities.
I a really stuck. Using {REPORT TICKET DETAILS:T.Id,EN.Customers} I can retrieve the customer name for each ticket, but I cannot find any documented way of retrieving the Entity ID.
Can someone point me in the right direction?
Also Using the tag I listed above to find !=0 accounts… Does then mean that the filtering is happening within the SQL server (I guess via WHERE), or are all Entities being returned to the SambaPOS terminal and only filtered as they get displayed by SambaPOS. Reading around, I am guessing that it is the latter, and if so, is it possible to write this tag in a different way so the query is handled more efficiently by the SQL server?
Not sure on ID but as an alternative to ($2!=0) you could try constraint of;
(ET=Customers) AND E.Balance!=0
Or something like that, actual detail fields can generally be used outside of the brackets where actual specific configured constraints are in the brackets…
Also are you sure it should be E.Balance.sum?? Not convinced you would want to sum the balance…
I doubt it when doing it that way, not sure SQL would understand the $2 but might be wrong, the formatting bits etc after the : I think are samba side.
Yes, the .sum was wrong (I think it snuck in there from some early playing around).
But I cannot seem to use the Balance in a constraint for some reason, anyone know why?
Also, I noticed that actually SambaPOS keeps Entity names unique (the front end won’t allow multiple duplicate names), but, forgive me, this kind of seems a bit silly. Surely we should be able to have multiple people with a name of “John Smith”, as long as they have different Entity IDs, that should be all that matters. Without, we end up storing “John Smith 2” (or something to that extent), which then means that instead of storing the Customers “Name” in the “Name” field, we actually start storing their name and an arbitrarily created number - This doesn’t strike me as a good database structure?
Consider when you are trying to build automation for some process and you try to load the Entity “John Smith” and 2 (or more) of them exist… your automation breaks at that point… that is why it is not allowed to have duplicates for the primary field.
To overcome this, you can consider changing the primary field to something that will be unique, such as a Member ID or Phone Number.
I totally understand the importance of a unique primary field, but that’s why a standard relational DB would usually have a Customer table with ID and Name fields. The ID being the unique identifier which would be assigned ticket in a ticket table.
Also, in this case the Primary (or unique) field would be generated on INSERT in to the DB. It seems very strange to have the user type in the Primary field. For instance, if you look at the Entities tables, there is an ID which as far as I can tell doesn’t actually seem to get used, (instead relying on the “Primary field”) - But every DB I’ve looked at in the past (mainly CMS databases) would use the ID field for linking tables to one-another.
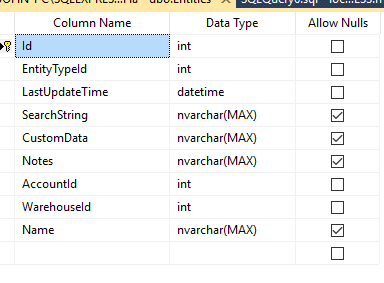
It seems that this “Primary field” linking is handled only within the SambaPOS, rather than being the true way in which the DB is setup, which seems unusual to me. For example, in the screenshot below, you can see that the “Name” field of the Entities table is not set-up as the Primary Key (The Key icon is next to the ID field, not Name). Also the “Name” field actually allows Nulls - which would make no sense as a true unique identifier.
I totally appreciate the amount of work that @emre has put in to SambaPOS, and it works brilliantly, but I am struggling to understand this non-conventional database setup. Maybe I’m missing something?
I don’t think primary field is the table key… Sure the table still uses a key/index using the ID value just you are required to specify a primary field which needs to be unique due to the use of entity name/primary field for selecting entity in automation.
Correct,the DB is the same as any relational DB, with the ID field being the Primary Key.
Correct, SambaPOS uses the user-defined primary field, and it handles control of that field to ensure that it is unique. Yes, this is unconventional, and is done with a few other tables in the system, but it is to keep the common user from shooting themselves in the foot. This is to abstract the workings of a DB from the user, and again, to ensure automation does not break.
You and I understand how a DB works. But a common user should not need to.
Yeah, I understand, but by forcing us to enter our own primary key (rather than using one that is hidden behind the scenes) it means we end up creating difficulties for the operators of the POS system.
What do you guys use as the primary key? It seems messy to have a combo of name and phone number, plus you then get in to the realms of how the data is added, leading to the primary key being unique, but not terribly useful. For example
John Smith
John-Smith
John Smith +1 2345 67 89
John Smith +1 2345 6789
John Smith +1 23456789
John Smith (234) 56789
Which one is correct? all are unique and it would be really unusual for an operator to always enter this information accurately. If we stored just one piece of information in each field that is offered to the operator then the chances of having bad data entered would be minimized.
I would use something like email address, but in truth we don’t need to know our customers email addresses, so I can imagine many customers not being too keen to give us this infomation, therefore we again would end up with a lot of inaccurate information being stored (such as [email protected]).
As far as I can see, it wouldn’t confuse the automation processes - Whenever we receive an [EntityName] this could still be a name, but behind the scenes it is looked up using the actual DB ID.
I don’t know how to explain this any better than I have already. It is unconventional handling from a DB perspective for sure. But it has been done this way for a specific purpose for the end user.
I am trying to explain why it has been done this way, and why it has always been accepted, and why it will probably never change.
You would not store the Phone Number with the Customer Name. You would just use the Phone Number alone, or a Member ID of some sort.
Just because the field in the Entities Table is called [Name] doesn’t mean that it must contain the Customer’s Name. That field could contain anything. When the Primary Field is defined in the Entity Type, that data (ie. a Custom Field such as Phone) will be placed in the [Name] field in the Entities table in the DB.
Consider the following action… if you try to load a Customer by their Name, and the Primary Field is actually defined as being “Name”, and you have 2 or more customers with the same Name, this action will fail. If the Primary Field has been set to Phone instead, then the Action will look for the Entity via the Phone instead. In fact the [Name] field in the DB will contain the Phone Number, which should be unique. The Customer’s actual name will be stored as a Custom Field instead, and SambaPOS does not care if duplicate data exists in Custom Fields. It is only concerned with the Primary Field.
Yes, I understand that, but that means having to ask for a phone number very early in the new customer process, or having to create our own membership number - so we need to have a separate system or list of membership numbers for the operator to enter. Surely it would make sense for the member number to be the CustomerID which would be generated on creation?
In terms of retrieving data by customer name, you wouldn’t. First you would find the customer (by searching by name) this would give a list of 5 John Smith’s and when you select one of those 5’s their customerID would be used to load further data. This is how every Content Management System I have ever seen works, but I know this is probably not something that’s going to change, so I should probably just drop it and give clear instructions to my operators of the need to create a unique primary key for all new customers which we won’t actually use for any specific purpose.
Going back to something I was saying earlier, actually, it seems like the .sum is required, because when I use this:
CSV list of customers who have non-zero balances
{REPORT ENTITY DETAILS:E.Name,E.Balance:(ET=Customers):{0}({1})::($2 != 0):,}```
I get this:
<img src="/uploads/default/original/3X/0/4/043ecd0e6b0f8c02844b6b3f293bdd2f11982e49.png" width="378" height="91">
But when I use this:
```[Table1]
CSV list of customers who have non-zero balances
{REPORT ENTITY DETAILS:E.Name,E.Balance.sum:(ET=Customers):{0}({1})::($2 != 0):,}```
<img src="/uploads/default/original/3X/0/e/0e51075f12e360f213890fa336a68620d5683a90.png" width="378" height="91">
What am I doing wrong, and is it possible to do this as a condition instead of one of these display filters?
@mjb2000 I think you’re incorrectly approaching the issue. Instead of questioning database structure it will be a good idea to share details of your case and we can talk about that.
So Do you want to auto generate primary field value for customers?
Other question…
That seems fine to me… Does it generate incorrect totals? Why do you think you’re doing wrong?
Yes - I would like to auto-generate a primary field for customers, but have an operator able to search for customers by name (when searching for an entity) For example, I would expect to find several people called “John Smith” - The operator would select the right entity based on knowing some other detail about then (address for example of our most frequent customers).
Using .sum works perfectly and gives the results I am looking for, but above @JTRTech questioned why I am using E.Balance.sum, he suggested just E.Balance should work.
So you have customer addresses but not phone numbers? Having phone numbers is a good way to validate a customer especially when you open accounts for customers. On the other hand when you use Caller-ID devices that works fine as SambaPOS automatically searches by primary field (phone number) when someone calls.
($2 != 0) is a group expression. That is useful when you need to filter a report that calculates by using a custom expression. For example I copied this from profit / loss report.
As you can see there are fields that calculates some averages based on $3 and $4 values. So if you need to filter report by % of the Profit for example you need to filter by a calculation and group expressions makes it simpler.
On your report you’re benefiting from grouping expressions to filter your report. However it enables when report contains a grouping expression like .sum so removing .sum disables the expression.
Instead of using .sum you can use E.Name.asc. It will enable the expression, you won’t have unnecessary .sum and values gets sorted by name.
Ahhh - OK, this is making a lot of sense now. Thanks for explaining. So is filtering like this the correct way to do things, or should I be using a condition in some way? I just couldn’t work out how to use E.Balance as a condition?
It all depends, with different customers we end up with different information. My main wish would be not to have the operator have to make up additional data to satisfy a unique primary key. Even if we have two John Smith’s with no other information. We would still have separation of the entities and for instance we might see that one was a customer who had 3 tickets from 5 years ago and this new John Smith has just this newly created ticket. In hindsight, we could edit the entity and add a note such as “the guy who really liked turtles”.
I think my point is that for us, most fields for an entity should be optional. If we have time and it is appropriate to enter additional information it can be entered, but having to ask for an unnecessary email address or phone number just to satisfy the requirements of the POS system seems like it becomes a burden on the customer flow.
This is not a POS requirement. I added this constraint to help people. If I remove that in a short period you’ll see tens of John Smith’s and all will be the same person because operators generally prefers to create a new customer record instead of dealing with existing customers.
I understand that, but I am still unclear on the best practice to accommodate multiple (different) customers called John Smith. I know this is a minor use-case, but what I am describing is completely in line with standard database design and normal usage scenarios of CMS and CRM systems.
What about using E.Balance as a condition? Is this possible, or should I stick to using it as a filter?
Th[quote=“kendash, post:18, topic:14056, full:true”]
A best practice is to use Phone Number.
[/quote]
That seems to be a popular opinion. Obviously I can do this, it’s just a shame it’s not something that can be handled automatically instead of my staff having to ask for information we don’t always need. Fair enough, seems like I am the only one who sees this as an issue
I am curious are you using this for a restaurant? This is not a CMS its a Restaurant POS that has the capability to behave like other systems, however it is designed to be a restaurant POS so features will be focused for that.