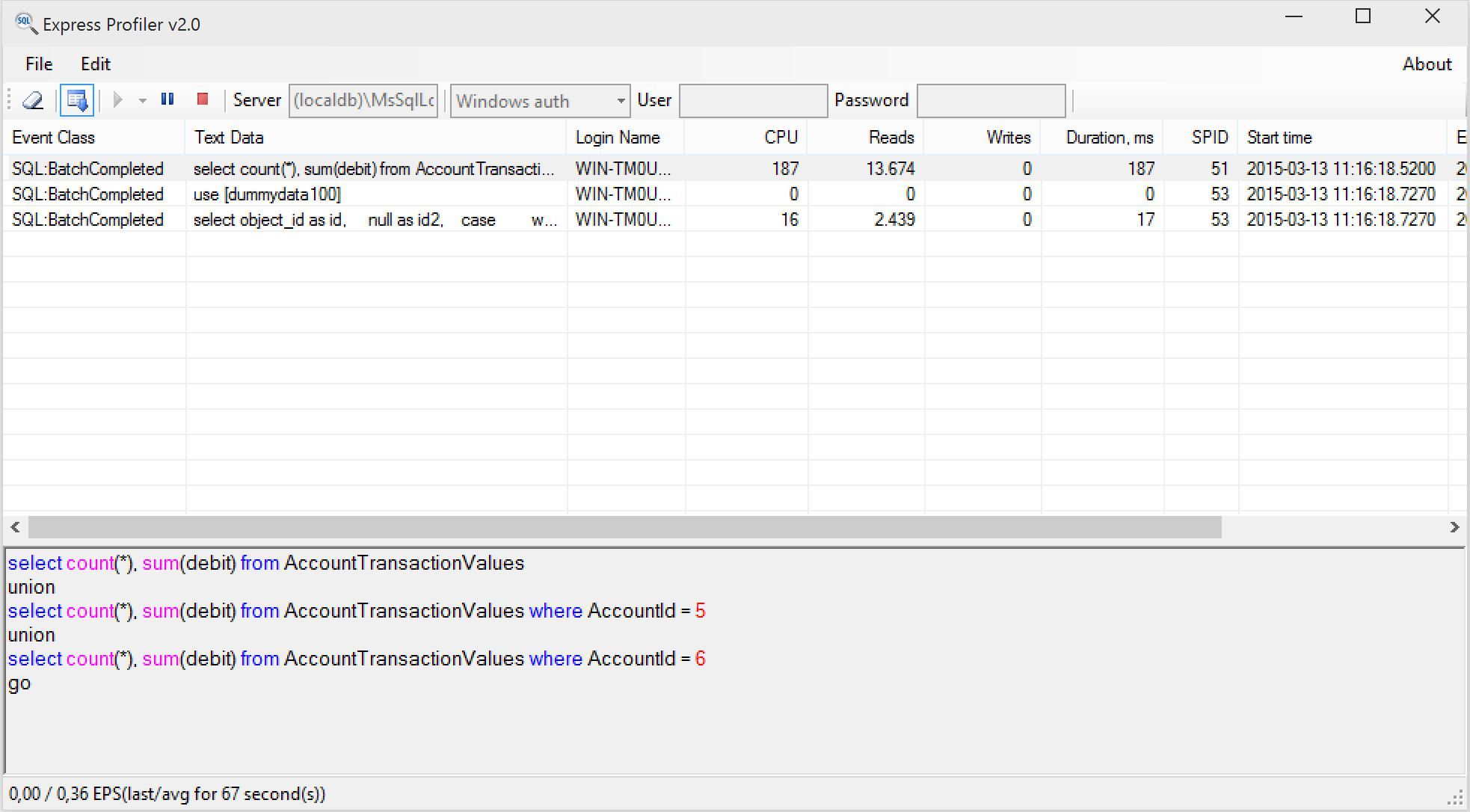
As time goes on, the size of the Database continues to grow with every Transaction that is made. The busier your business - the more sales that you do - the quicker your DB will grow.
Since running for just over a year, my DB contains approximately 85000 transactions (which nearly doubles in the [AccountTransactionValues] table to over 170000 rows) and the size of the DB is about 250 MB.
While there is a simple method to delete all Transactions and set your DB to “new”, this method will also wipe out all Account Balances - which might not be desirable in a lot of cases.
I want to start the discussion regarding a method by which we can remove all Transactions, yet leave Account Balances intact. Simply, I want to reduce the size of the Database without affecting Workperiods (Z-numbers), Ticket Numbers, and Order Numbers.
Open to all comments, suggestions, insights. Let us hear what you have to say in regard to DB size and performance.
An archiving feature might be good here. I am thinking something that operates similar to rule export but it would export transaction data instead of making copies. Accounting could be amended someway to preserve the numbers. But since the accounting is linked to transactions this might be more complex.
well… I think we should create even more data and delete nothing. If increasing data leads to slower operations we should solve that by improving SambaPOS features. I’ve tested it with +30M transactions but we may still have places that needs improvement.
SQL Express has 10 GB limit so increasing database size should not be a problem in the near future. V5 data access framework also upgraded to a new version so we’ll probably have options to use other databases as well.
Data collecting and processing technologies constantly improves (we even have programming languages just for that) and when I complete some side SambaPOS projects we’ll process terabytes of data
So in short don’t care increasing data and if you notice slow performance somewhere just create a backup and send me your database for deep analysis.
I thought I might be experiencing degradation in performance in V4… from time to time, the system appears to “freeze” for a moment before responding to recent input. This prompted me to question the size of the DB and the number of rows that it needs to process in certain cases.
Recently, I did a few things, and I haven’t seen this issue.
Upgraded from i3-3xxx to i3-4xxx.
At the same time, I moved from Win7 to Win8.1
Increased RAM from 4GB to 8GB.
Began running V5.
Upgraded from 5400RPM 500GB HDD to 250GB SSD (Crucial MX100).
The last 2 points (V5 with SSD) have made a noticeable difference, and I no longer suffer from “pauses”. I am not clear on which of the 2 points really made the difference - it may be a combination of both.
If you consider that an HDD will fragment your files, and the larger the file, the more opportunity to fragment that file, thus reducing performance. Even with regular defrag maintenance, the file is still large and will become fragmented quickly in a short period of time, and data will be placed at the “end” of the disk - the “slow” part.
So does this make a difference in performance? Or is it only constrained to initial start-up of the DBMS? Does it load the DB into memory and not care to access the disk? I don’t think so, but I could be wrong… maybe there is a way to force it to do so - still you need to write to disk, so would it matter anyway?
Anyway, all of this is what prompted me to ask the question: can we reduce the size of the DB?
Could we for example, archive the data into summary tables which still gives use insight into business performance over time, while removing the increasingly massive number of rows? Of course we can! The question then remains: how do we go about it?
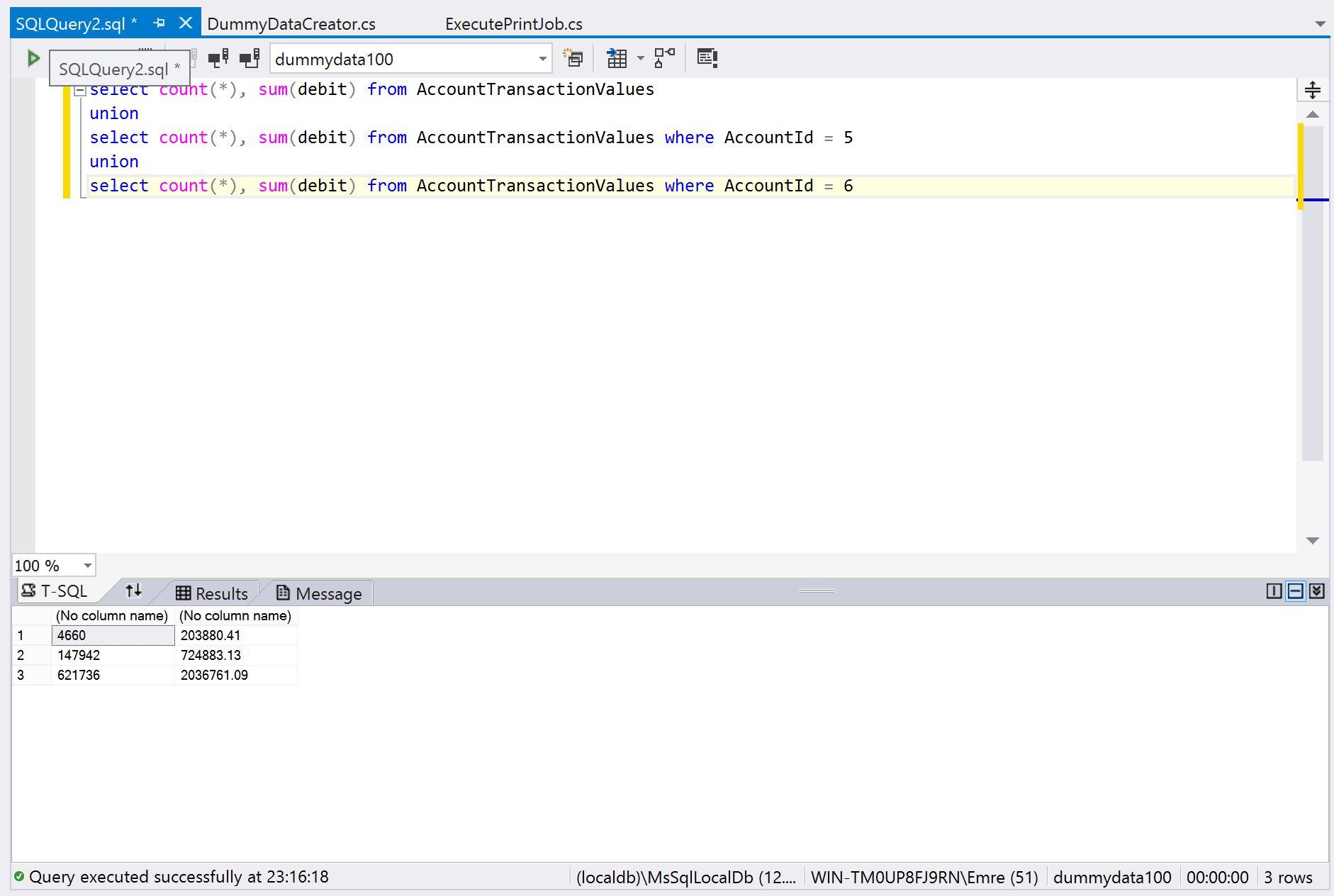
I’ve just randomly created ~150K tickets. That makes about 300K transactions and 600K transaction values. There is no significant performance degrade at all. No change while creating tickets. Maybe a half second lag for default account transaction screen but that can be optimized via background processing. I’ve also created a tricky query to test how fast it can make calculations.
I mean querying a single account balance through 600K values does not take more than 100ms and sql server is intelligent enough to cache, optimize frequently calculated values.
Fragmentation is not an issue as it creates a single file for entire database. Fragmentation is a file mapping issue that generally relates with creating / deleting a lot of small files.
Deleting them will be easy by deleting tickets, account transactions and inventory transactions that is older than a specific date and creating a single transaction document that contains carried values. But we should think about what we’ll achieve by doing it.
Yes - this is a common issue in most POS systems with data 2/3+ years old.
I have written interfaces into a few SQL based POS systems and there is a clear difference in “Clean Up” to “Archiving”:
Cleanup - Remove transaction data only older than say 2 years on wards (a transaction being any record data which is created for adding a sale/receipt and does not include Master data such as Products, Customers etc);
Archiving - Removing transactions as described above BUT placing them in a format which can be easily accessed preferably by the POS.
The Cleanup is the easiest option as the transaction data is deleted based on a user specified data, files packed and all system go.
The Archiving typically requires the full creation of a “second” database which can be switched to or accessed by the POS. Archiving can be tricky because you will need to Archive again in a few years so the questions arises - “Do you create another System”? OR “Do you append old data into the 1st Archive”?
If you wish to be neat and look at a good historical base then you would APPEND but this infers you need to make sure ALL Master products exist/menus exist/ rules exist etc etc…
For my 2 cents worth (and experience) - once the data is old it is dead. The client rarely wishes to go back into the past and on that rare occasion I suggest review the historical reports that they printed out before archiving (cheeky). Archiving is the “ducks nuts” but requires a lot of work and has a many forms of implementation. The Archive Systems I have written were almost “Systems within Systems”.
My thoughts, Paul.
[A man waiting for V5 and hopefully Multi Customer Accounts ]
PS - Pls link this as I could only create a new topic?
I was noticing one or two second “freeze” sometimes with our setup as well. Make sure you enter “0” for “Turn off Hard Disk after” in Power Options. HD is spun down and it will take 1 or 2 seconds to spin up again. I believe this setting fixed our issue. Now that you a have SSD, this setting should not matter.
I think adding a data purging feature is a great enhancement. I am sure SambaPOS does not have a problem with large SQL database.
A data purging feature will help with backup and restore. I backup SambaPOS database to a client computer and this client gets backed up online to Dropbox.
I delete SambaPOS data every year since I have no use for this data after one year. Deleting data keeps my backups every small and improve restore-ability compared to a very large database restore.
I have some great ideas how to implement this feature. Let me know if you decide to pursue this feature further and I can share some ideas.
When you write records to the DB, the file gets larger causing fragmentation if there are no contiguous blocks at the end of the existing file.
Very good to know that a large number of transactions does not affect performance in any noticeable fashion. Thank you for testing.
This is the other major reason I was thinking about “shrinking” the DB.
Please do.
I was into Data Warehousing in my previous occupation. I could probably come up with some scripts to archive off the data, but it would mean placing summary data into new tables that SambaPOS is not aware of. I want SambaPOS to be aware of this summarized data so that it can be used for Yearly/Monthly/Daily Reporting, etc.
IMHO data never dies. As years passes it improves our business memory and that creates a perfect infrastructure for artificial intelligence applications. In this era we should focus on keeping data of everything. Everything we can imagine. Every state change we can think. For example I don’t understand why people wants to correct mistakes by undoing. Every mistake correction should be done with additional transactions and this is also a valuable business data. We may not have enough analysis tools yet to give some concrete examples but as your business grows SambaPOS will also grow and as your business memory increases SambaPOS will become more intelligent.
Trust me purging data means loosing business memory and this is developer’s invention (and a bad idea) not to deal with big data. I’ve made a lot of optimizations (and still dobing) to keep operational performance steady as database size grows. If growing data causes issues we should solve them without deleting data. We should think different backup methods or query data differently. It certainly needs more development than just deleting data but I’ll recommend you to keep all data. Don’t delete. btw backup for 600K data took about 70MB’s. That makes about 10 high resolution photos.
Database servers allocates more space than it needs so it does not constantly increase file size. That’s why databases shrinks a lot when backed up. I don’t say it won’t cause fragmentation at all but deleting old records wont solve that.
This is something entirely different. While trying to reduce backup size we’re talking about things that will extremely increase reporting complexity. I don’t think it will be easy to implement one summarization method that will work fine for everyone.
After reading what @emre has said and from my own experience with data particularly data used for very intelligent metrics from my years with Walmart I must say I agree we should try to save everything.
That is a great tip for those with HDD. And as you say, with SSD, it doesn’t matter.
I completely agree with this. The data needs to stay. It just needs to be summarized from a Transactional View to an Aggregate View in a separate DB so we can reduce records in the Transactional DB, and thus DB size.
I don’t agree. When I first started using SambaPOS, my DB size was less than 10MB if I remember correctly. Now a year later, it is 250MB. I am talking about the MDF and LDF files combined. The MDF file (the big one of the two) must be fragmented. I will need to check this on my old system to verify, but I am almost certain this is the case (unless I had nightly defrag happening). Further, the BAK file is essentially the same size, so no real reduction is taking place unless you compress it with ZIP, or better yet RAR. Perhaps the act of doing a backup and a restore alleviates this issue to some degree?
OK. I understand your point. As I can remember by default it increases database size by %10. So your database will grow 25 MB per iteration. Can you check current fragmentation with sysinternal’s contig? I wondered how much it fragmented.
@QMcKay - have you had any results from “SHRINKING” the database? Of course you need to have deleted old stuff to get any space improvement. It also depends if changing rules/actions etc create “dead” copies (by design) as these may get cleaned up as well.
Notwithstanding @emre view, I typically shrink DB’s down from 250MB to 60MB every 2 years. The clients had no interest in the metadata and probably because of using a inferior POS right! @emre my goal is to eventually unleash a product like SambaPOS to actually use the metadata and as you said in an earlier post “change the whole customer experience” - love this concept.
It seems to be a fairly uncharted teritory with smaller business but its almost gold standard among large business to stay competitive and stay ahead of the game. However using data to form Metrics like KPI or Analytic Data to improve business will be a game changer once smaller businesses really figure out how to leverage it. I think SambaPOS has that potential to tap into this area. We just need to get more people educated and on board with it.
I dealt with it every day when I worked for Walmart and let me tell you they are masters at it. The magic they do with their data is unreal and almost seems like real magic lol.
This is just a side point but at some point the opportunity may come along that a business need requires this capability. Anyone that operates large multi site operations with 50+ establishments would need to rely on this type of data to stay competitive. It would be nice to know that SambaPOS would be capable to serve this business need one day.
My .bak file uncompressed is 280MB and I have been running this DB for 6 months.
I understand big data has value, but only if you know how to use it. I think the majority of us are still having trouble with Rules/Actions/Automation Commands. forget about analyzing data for trends and business intelligence. Large companies have dedicated departments just for this stuff.
280mb is not very big most people store terabytes of music or movies. I disagree that we should forget about something like this. Comparing this need to the learning curve is also not a good rationale. You could say the same thing about any part of the pos. I could say forget about improving data archiving when most of us still struggle just to print something.
Instead of taking that approach lets look at what we can do to make something better. We should never settle for less just because we don’t understand it.
That was just a very small example of what you can and should do with business data.
What you said really only reinforces the fact that there is huge opportunity in small business to leverage these tools.
BTW some quick math would tell you if your 6 month database size is only 280 mb then after 10 years you would have only used 5.6 gigs… that is very very very small amount of data. More than likely your hard drive would die and be replaced before it even got to 10% capacity.
I am not comparing my DB size to SambaPOS learning curve. I was trying to stay that using big data for business intelligence is simply beyond most people capability.
Additionally, we are not proposing mandatory data deletion. This will simply be an option for people that want their DB to be small.
My concern is not with database size on the local disk. My POS has 1TB local storage, so 5GB is tiny compared to HD capacity.
I need to keep my DB small because I uploaded it to Dropbox. 560MB takes 2-3 hours to upload with DSL upload and Dropbox has 2GB free storage. I also want to ensure quick restores if server stops working. I do not have any experience restoring 5GB SambaPOS database, so I can not speak for recoverability. Recoverability is another important aspect of backups.
So Microsoft SQL express 2014 has a database limit of 10Gigs and Microsoft SQL is really expensive… Has anyone looked into MYSQL its free and that database size has like a 2TB limit.
If for some reason you need more than 10gb (would be nearly impossible to fill that much) you can upgrade to Microsoft SQL 2014 instead of SQL Express. This means yes you would need to pay for it.
The entire software would need to be rewritten more than likely for it to work with MySQL.
Personally if we ever got the ability to choose database types I would prefer PostgreSQL